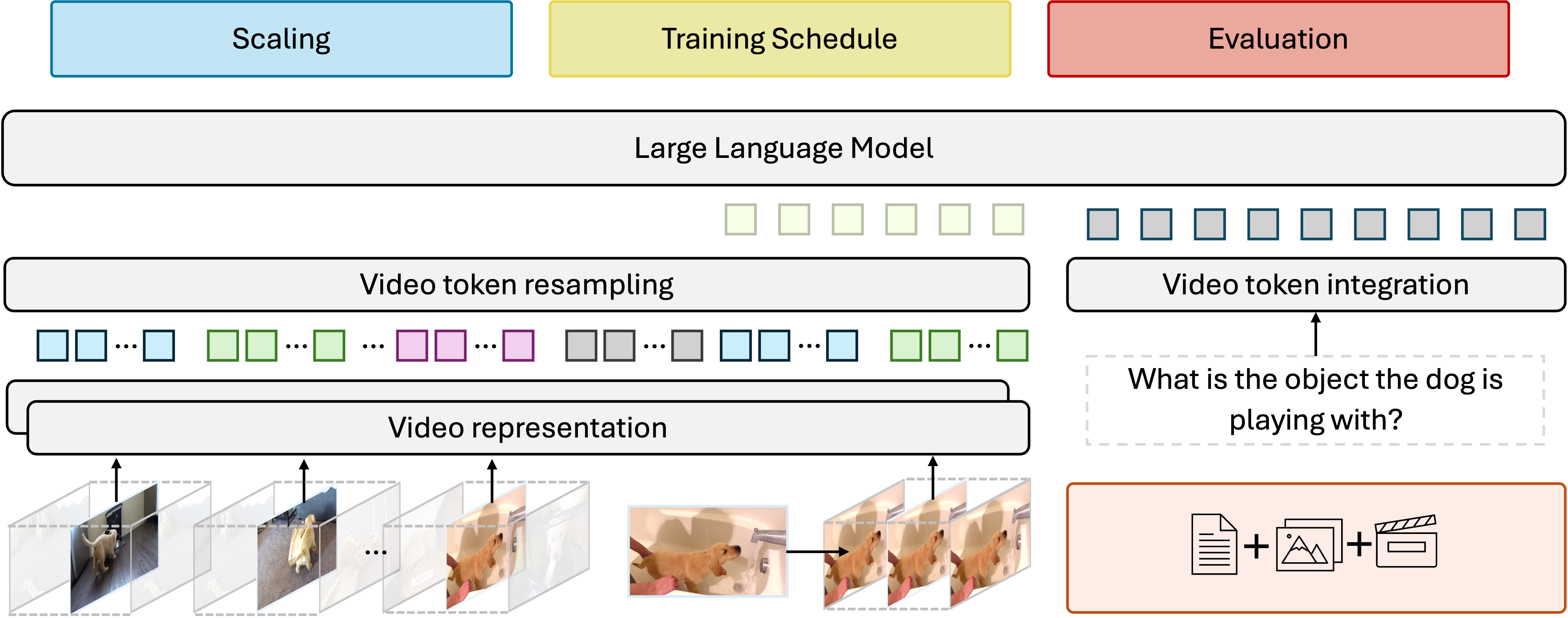
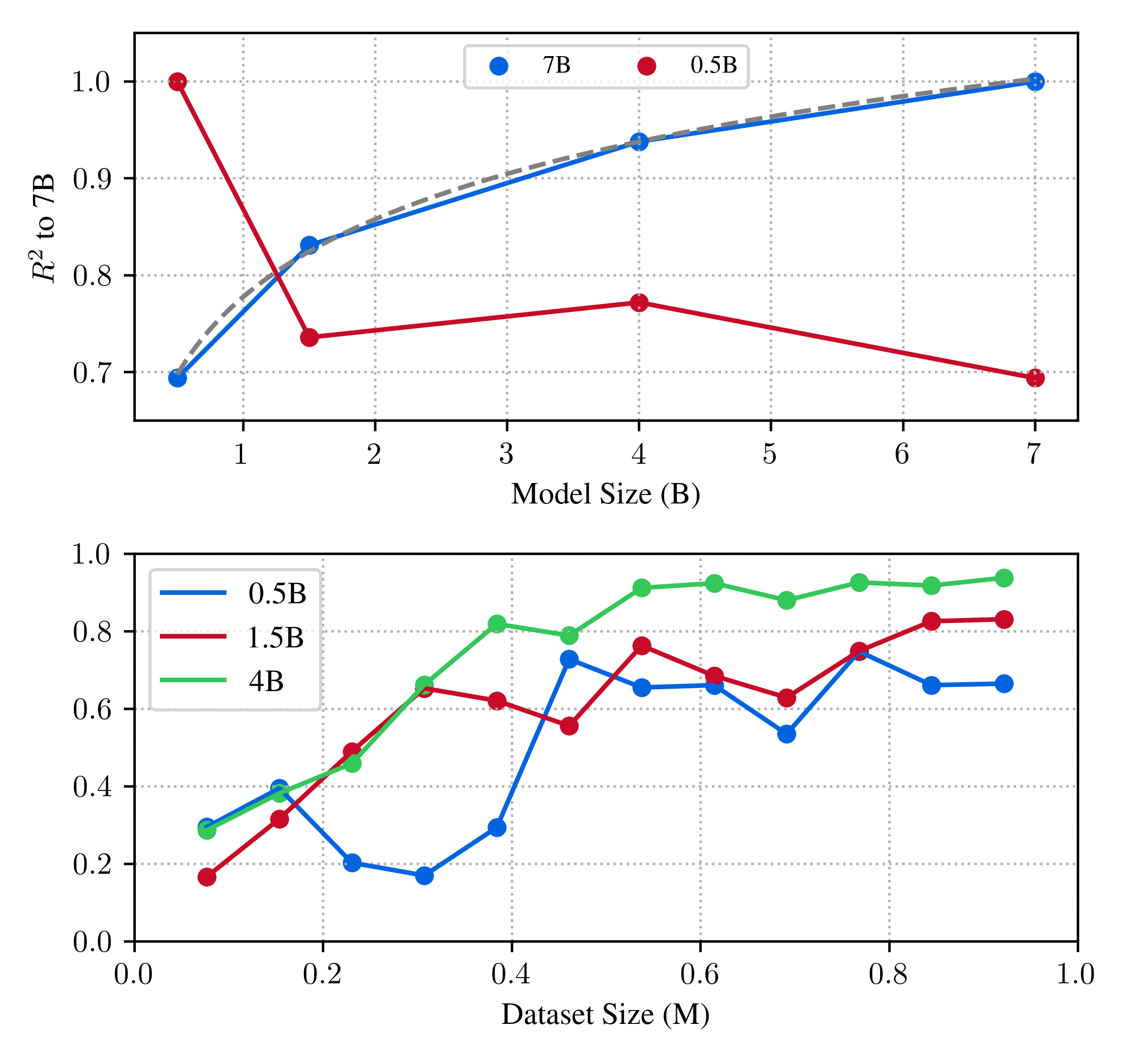
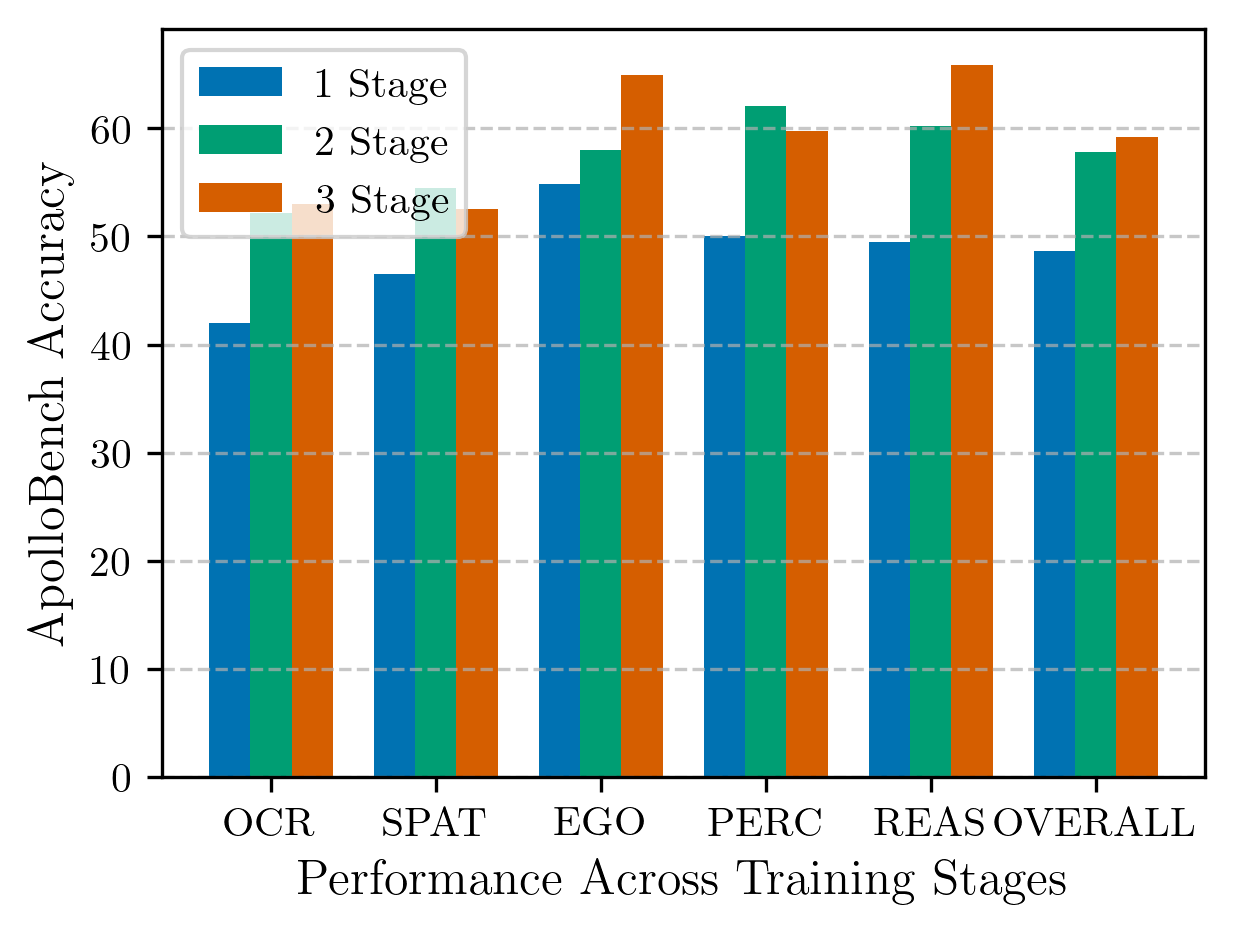
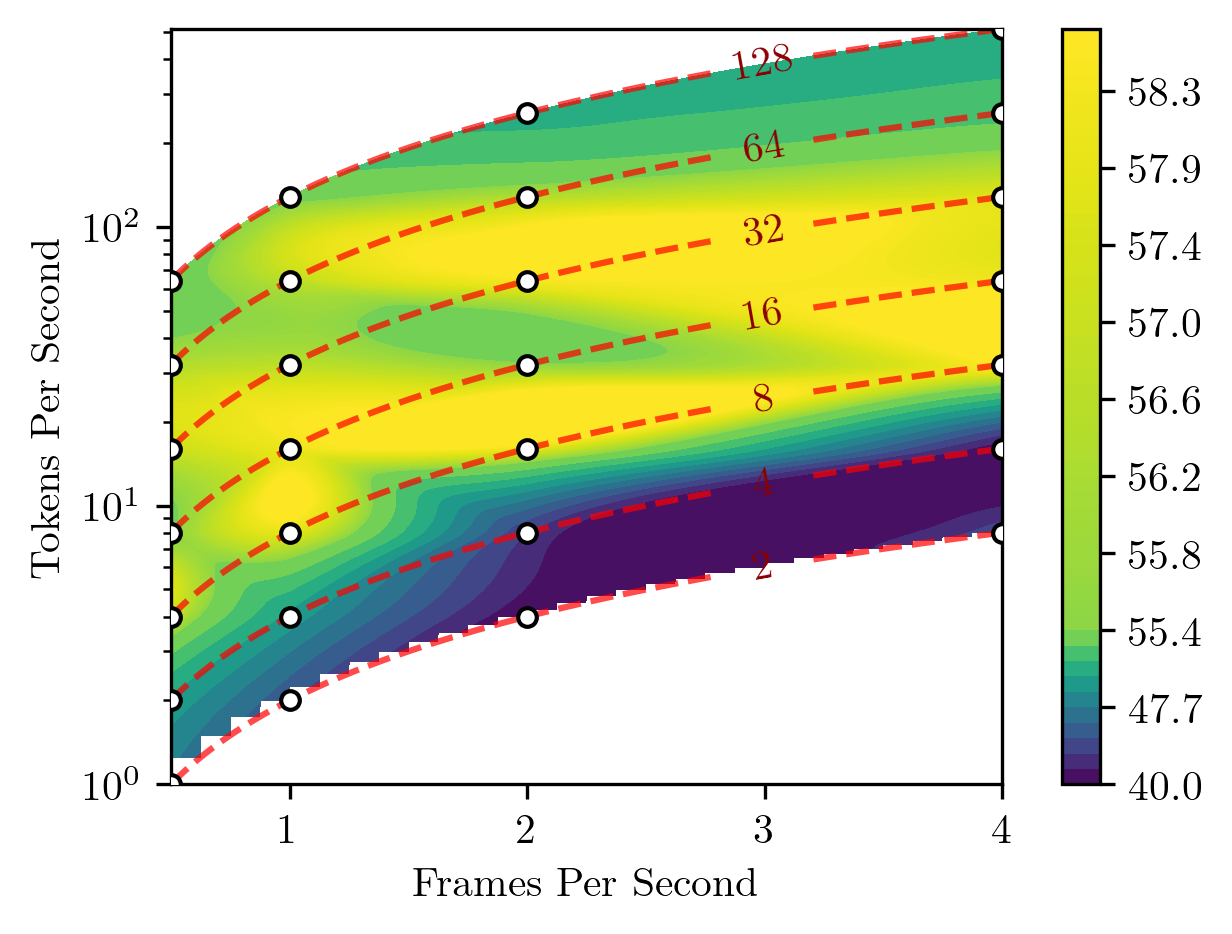
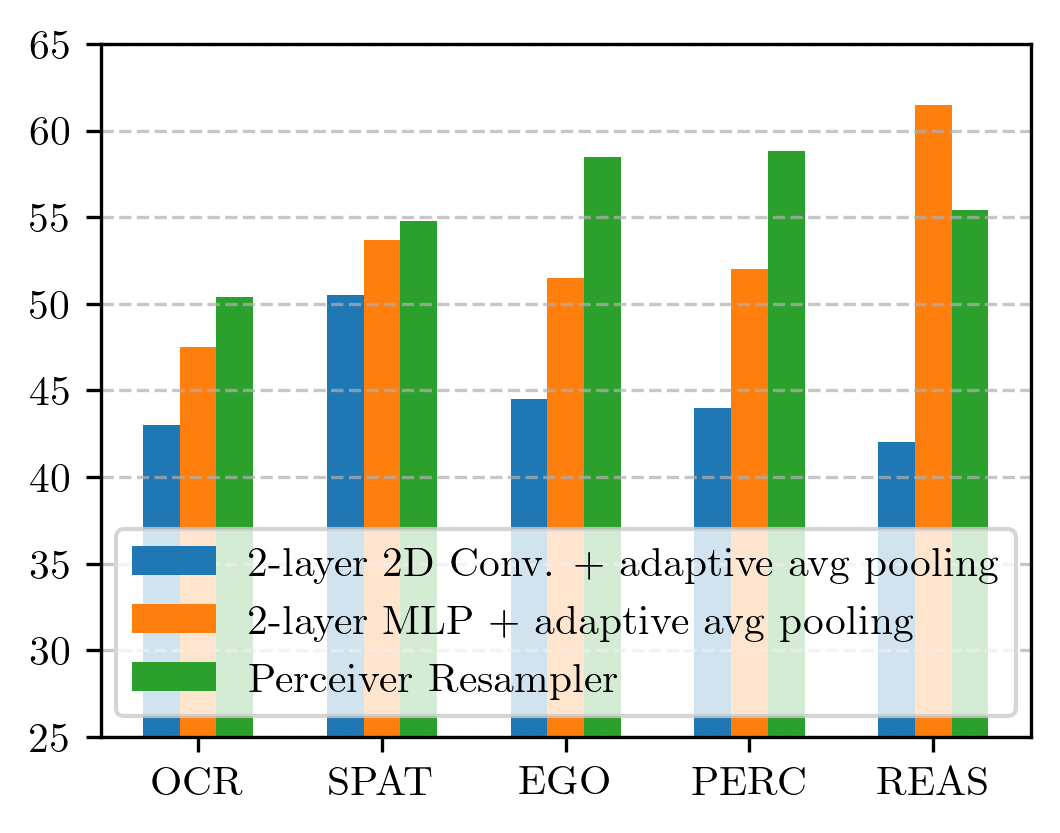
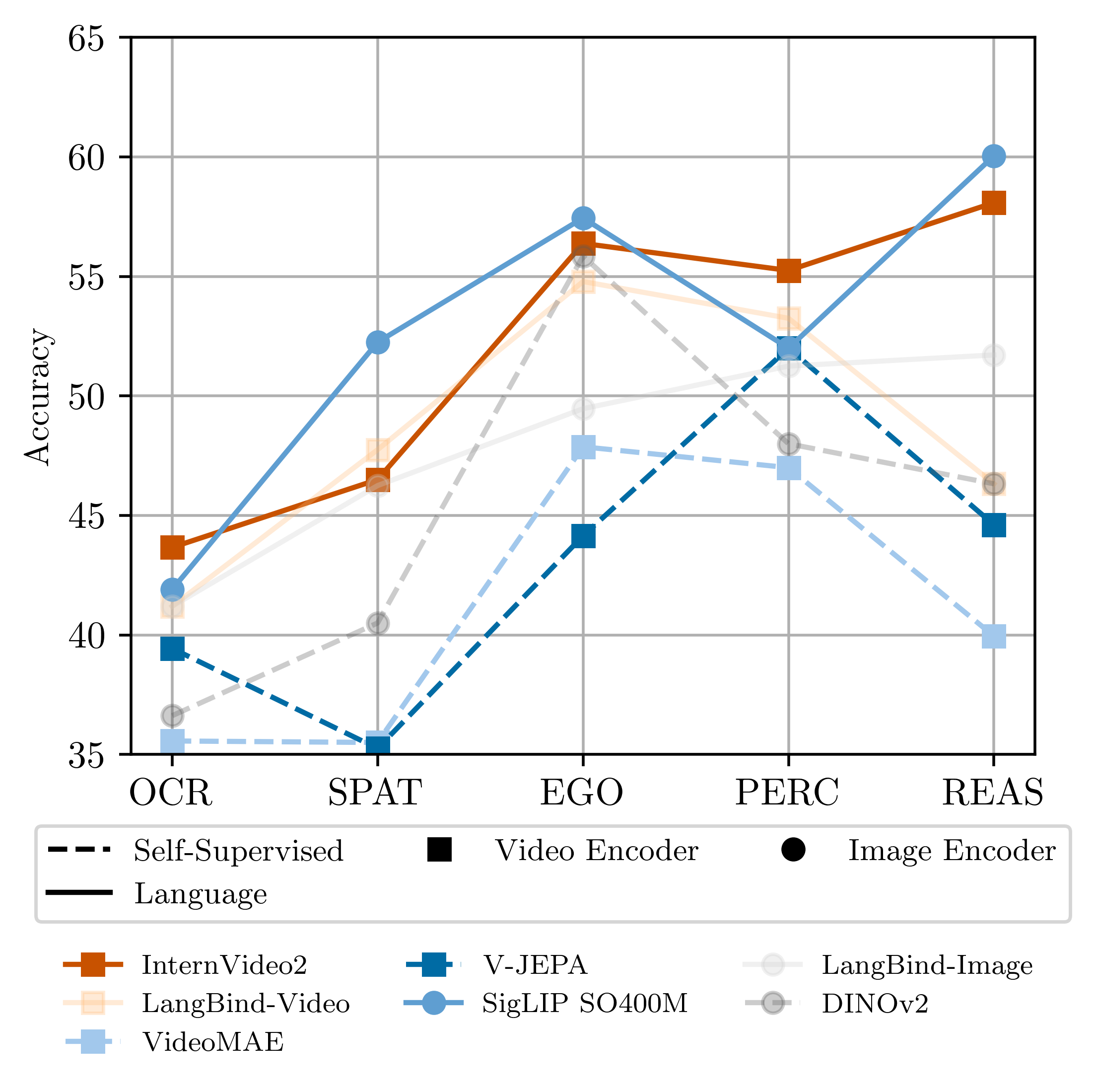
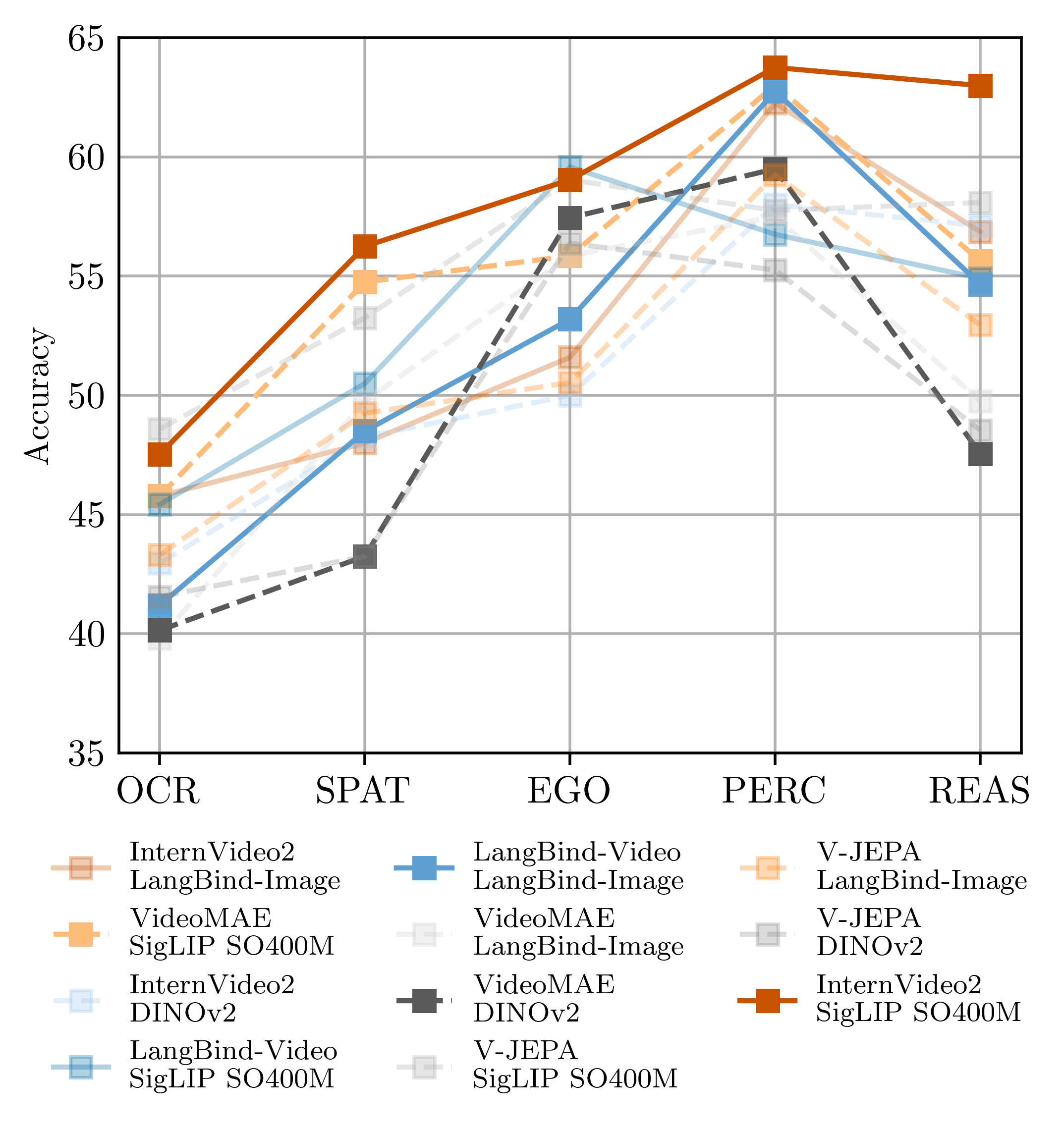
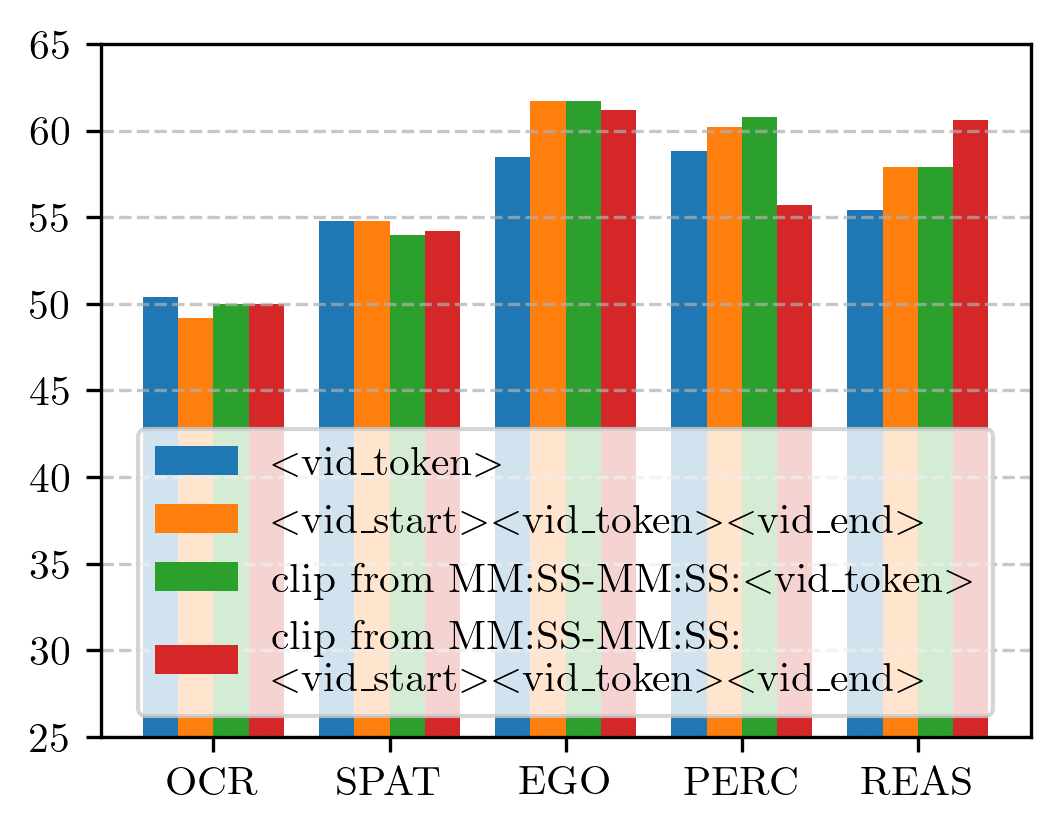
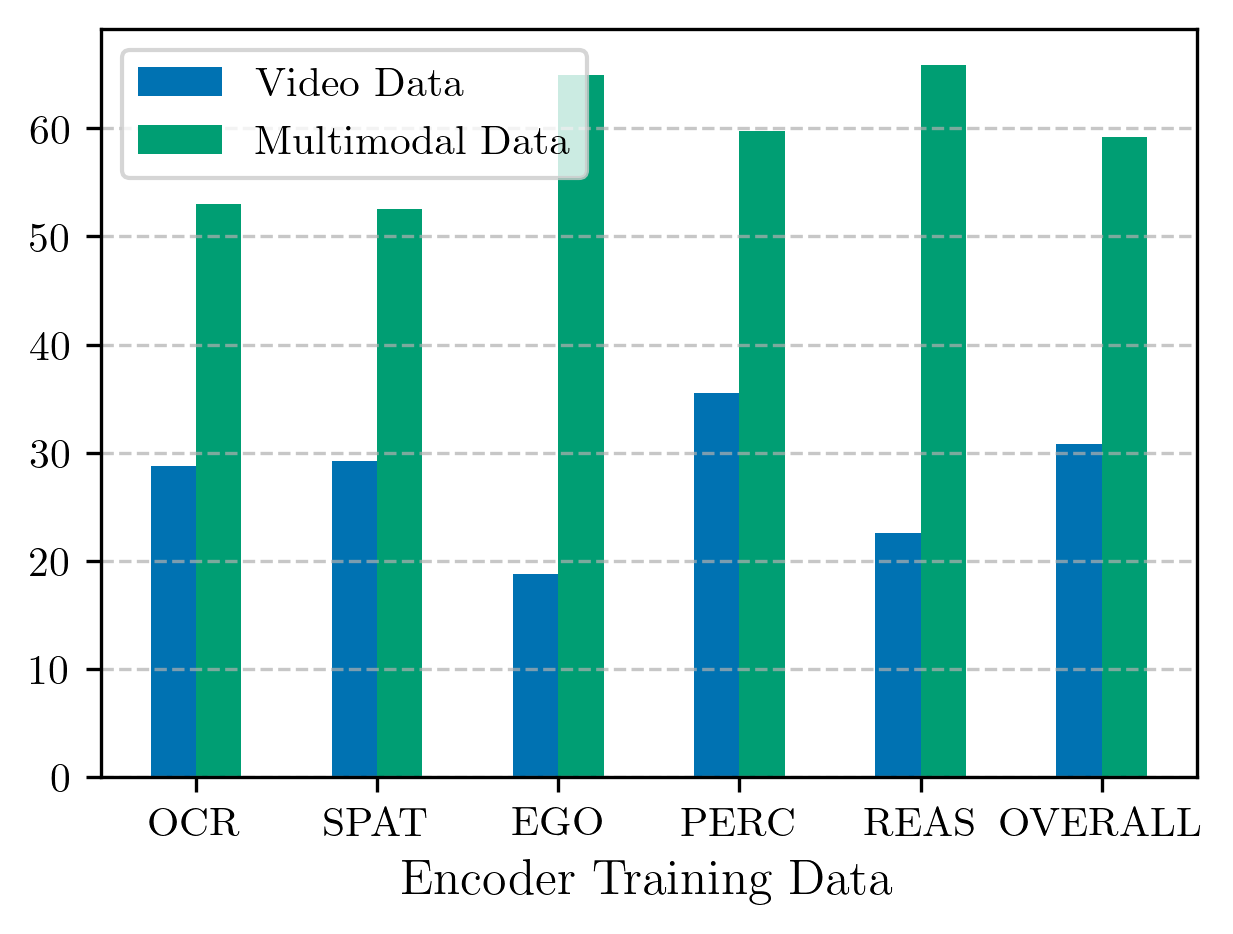
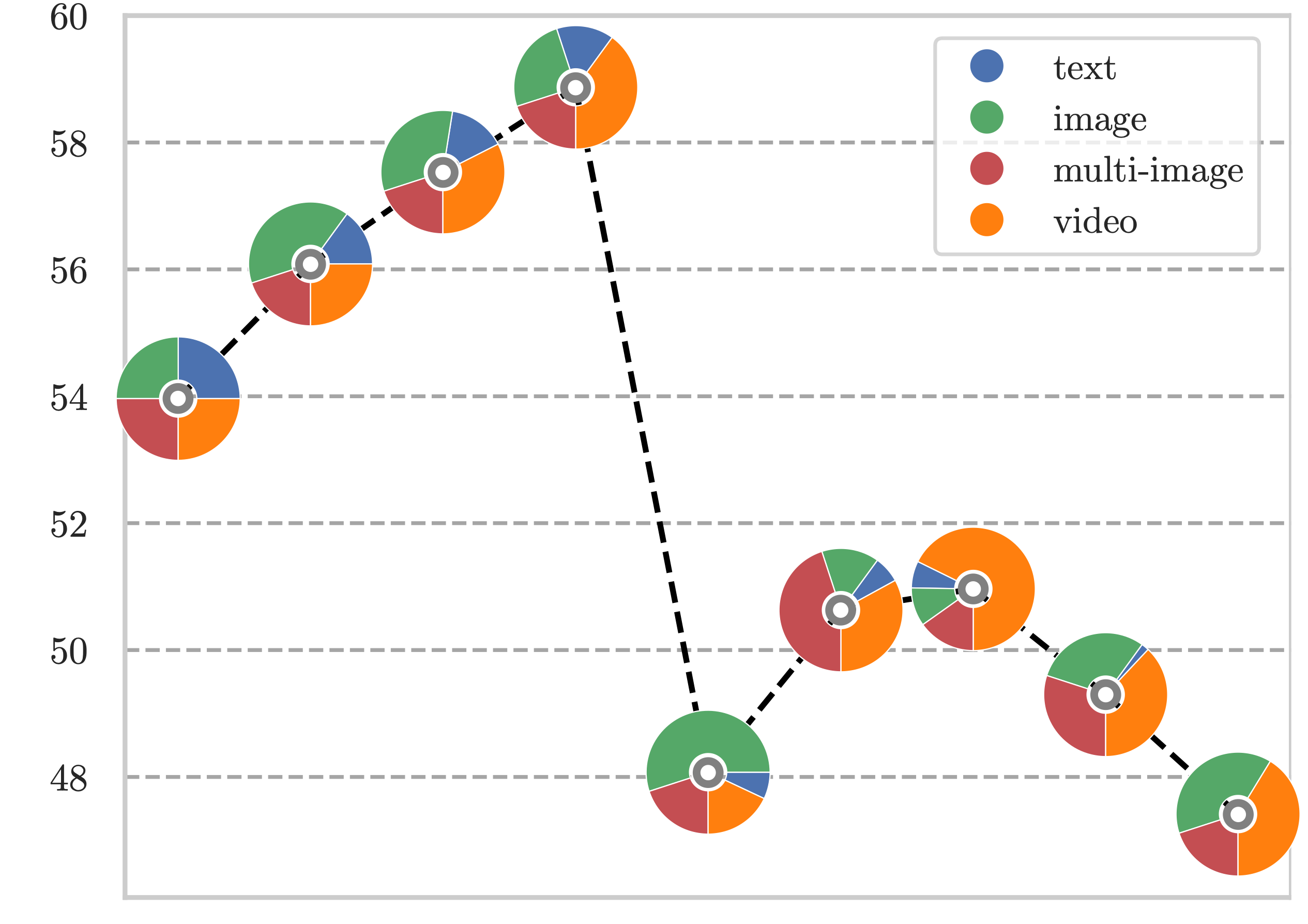
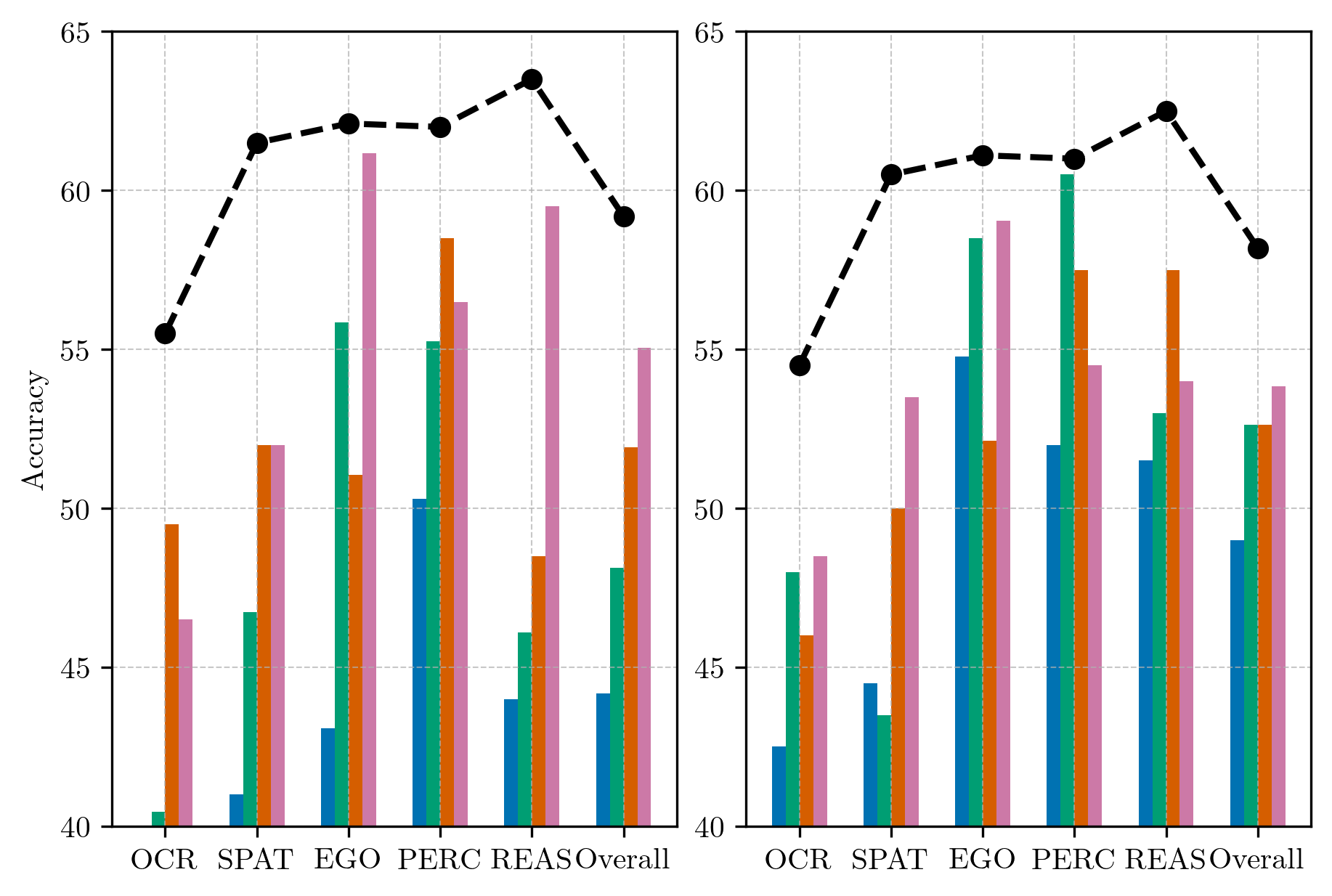We introduce Apollo, a new family of state-of-the-art video-LMMs. In developing Apollo, we uncover Scaling Consistency, enabling us to reliably make design decisions on smaller models and datasets, dramatically cutting computational costs. Guided by these principles, we train hundreds of model variants—systematically exploring video sampling strategies, token integration, training schedules, and data mixtures. Leveraging these insights, Apollo sets a new benchmark in efficient, high-performance video-language modeling.